谷歌 DeepMind 推出两款新型 AI 模型,旨在帮助机器人完成更多现实世界中的任务
670 2025-06-29 00:00:00近日谷歌DeepMind推出两款新型AI模型,旨在帮助机器人完成更多现实世界中的任务。
其中一款名为GeminiRobotics,是一款视觉语言行动模型,能够使机器人在没有进行过专门训练的情况下理解新的情境。
GeminiRobotics基于谷歌最新版本的AI旗舰模型——Gemini2.0。谷歌DeepMind机器人部门高级总监CarolinaParada曾表示,GeminiRobotics依托Gemini的多模态世界理解能力,通过加入物理行动的新模态,将其应用到现实世界中。
该模型在谷歌DeepMind认为构建高效机器人所需的三大核心领域取得了进展:通用性、互动性和灵活性。除了能够应对新的情境外,GeminiRobotics在与人类及环境的互动上表现更好,且能够执行更精确的物理操作,比如折纸或打开瓶盖。
另一款则是GeminiRobotics-ER(具象推理)模型,公司称其为一种先进的视觉语言模型,能够“理解复杂且动态的世界”。
Parada进一步解释道,当你在装便当盒时,桌上的物品摆放位置和如何操作是你必须考虑的内容。GeminiRobotics-ER正是为此类推理任务而设计,机器人专家可通过该模型与现有的低级控制系统对接,开启由GeminiRobotics-ER驱动的新功能。
谷歌DeepMind的研究员VikasSindhwani表示,公司正在开发一种“分层安全策略”,并称GeminiRobotics-ER模型已被训练用于评估在特定情况下某个动作是否安全。公司还发布了新的基准和框架,推动AI领域的安全研究。据IT之家了解,去年,谷歌DeepMind推出了“机器人宪法”,这是一套受艾萨克・阿西莫夫启发的机器人行为规范。
据外媒TheVerge,谷歌DeepMind与Apptronik合作,共同致力于“打造下一代人形机器人”。此外,谷歌还向包括agileRobots、AgilityRobotics、波士顿动力和EnchantedTools在内的“受信任的测试者”开放了GeminiRobotics-ER模型。Parada表示:“我们专注于打造能够理解物理世界并在其中行动的智能,我们非常期待将这一技术应用于多个领域和多种表现形式。”






热门资讯
-

- OpenAI将终止对中国大陆提供API服务,把握替代ChatGPT机遇 国产大模型寻求技术变现
- 814 2025-06-12 10:15:50
-

- DouZero: 基于自我对弈深度强化学习的斗地主AI系统
- 1011 2024-12-19 02:10:32
-
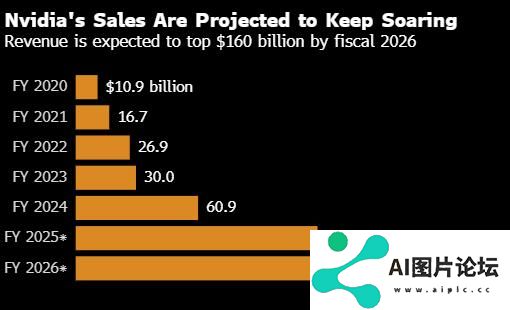
- 英伟达会是又一个思科吗 AI产品需求前景成为多空争论焦点
- 1824 2025-06-11 12:36:29
-

- 上海首届青少年AIGC创新艺术展开幕,让孩子掌握AI技能
- 901 2025-06-11 14:36:29
-

- 高校开设人工智能专业不宜大干快上
- 1961 2025-06-12 09:03:50
-

- OpenAI“停服” 国产大模型争抢“平替”市场
- 1738 2025-06-12 10:39:50
-

- “AI换脸”是否涉及法律责任?用AI技术“换脸”,哪些底线不能碰?
- 838 2025-05-30 10:49:25
-

- AI模型可提供快速可靠的心脏健康评估
- 1378 2025-05-30 13:37:25
-

- AI赋能产品迭代 创新药产业链发展向好
- 1855 2025-05-30 14:49:25
-
- 成龙新片用AI换脸?网友争议:AI效果不尽人意
- 502 2025-05-30 15:37:25










相关常用工具
查看更多- 1 Okaaaay 1204
- 2 GrammarGPT 944
- 3 unbounce 187
- 4 论文智匠 348
- 5 WiziShop 1616
- 6 Easy-Peasy.AI 1809
- 7 Botowski 940
- 8 Shakespeare AI Toolbar 1402
- 9 nichess 607